Abstract

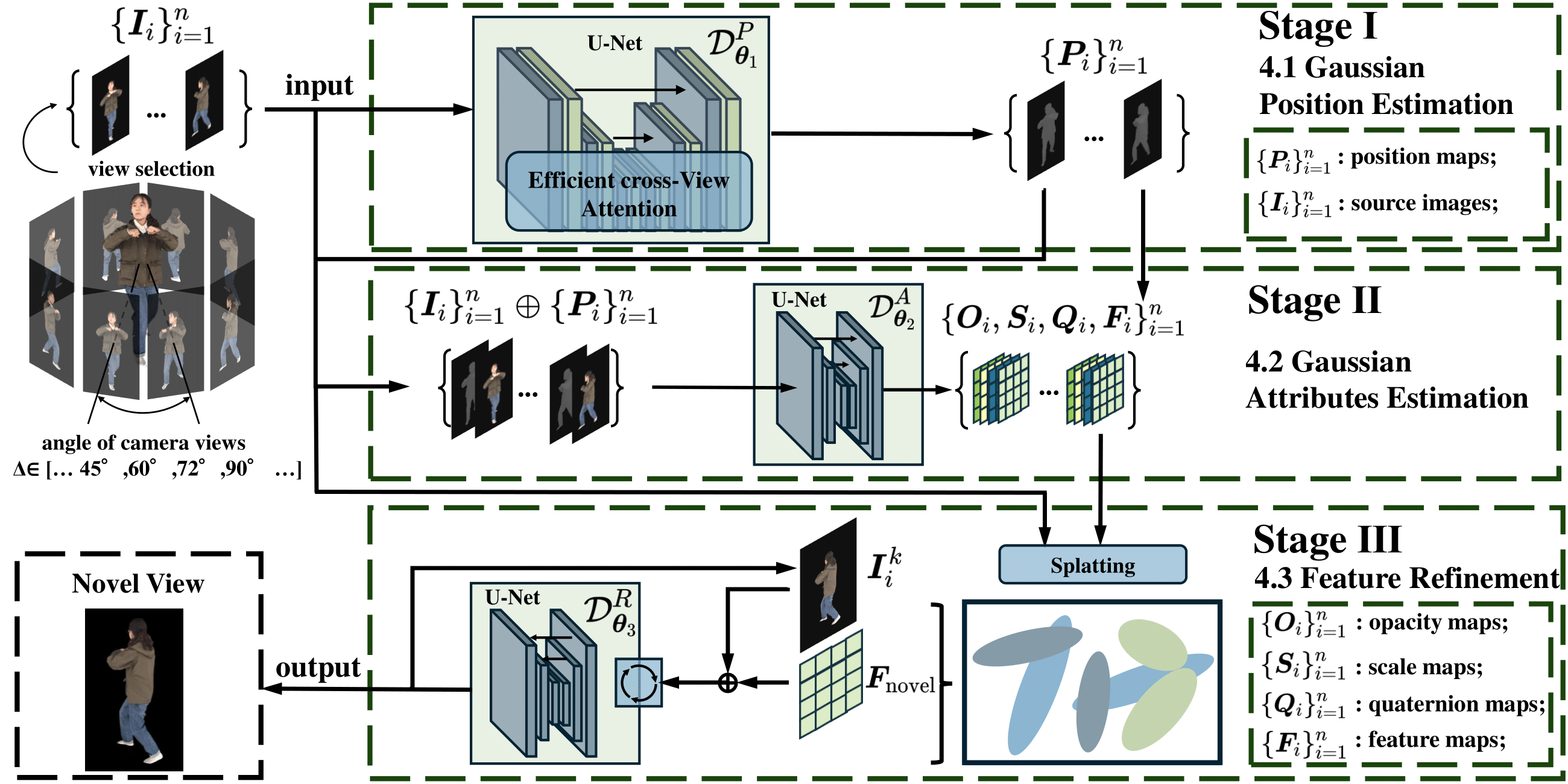
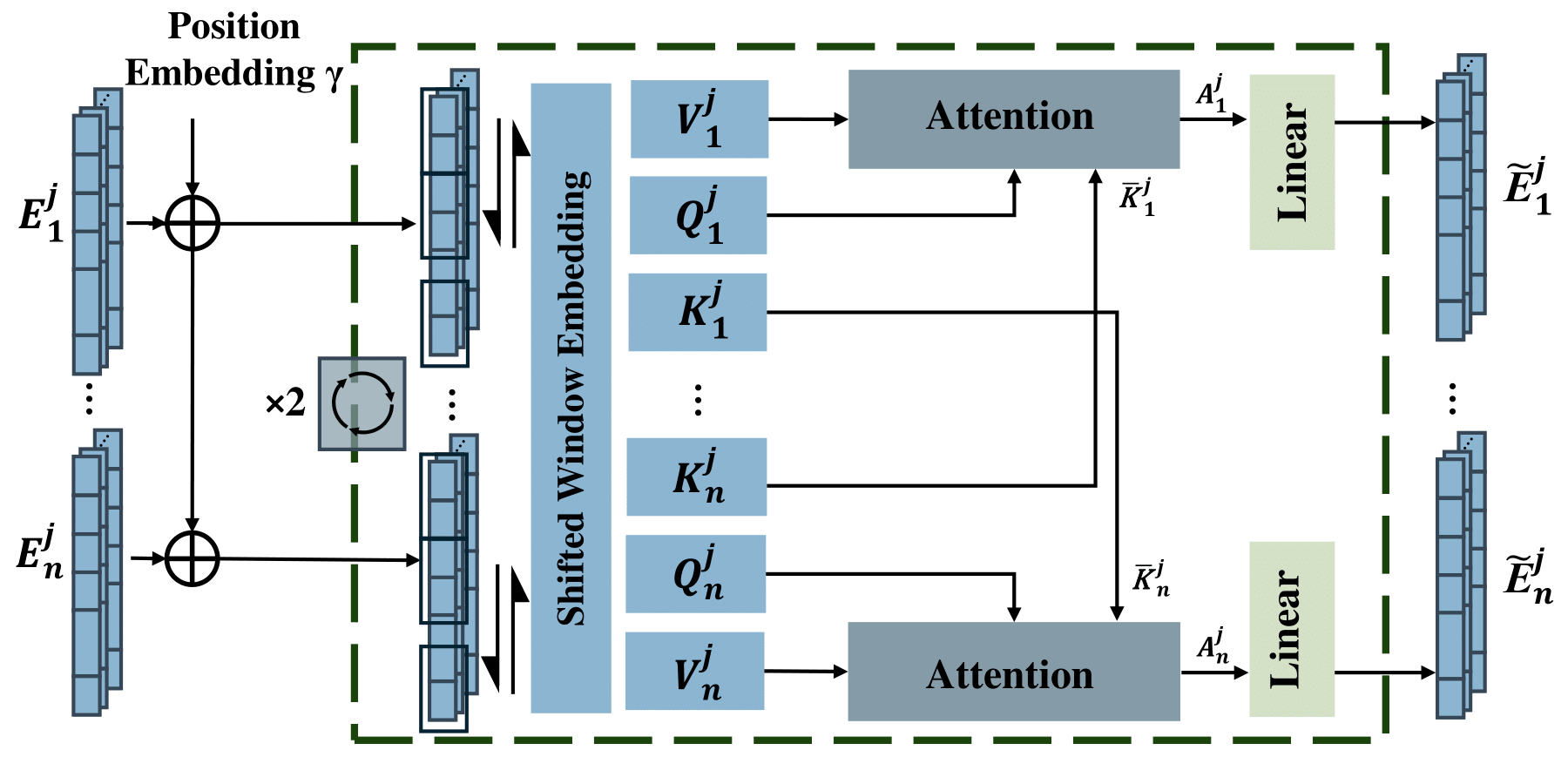
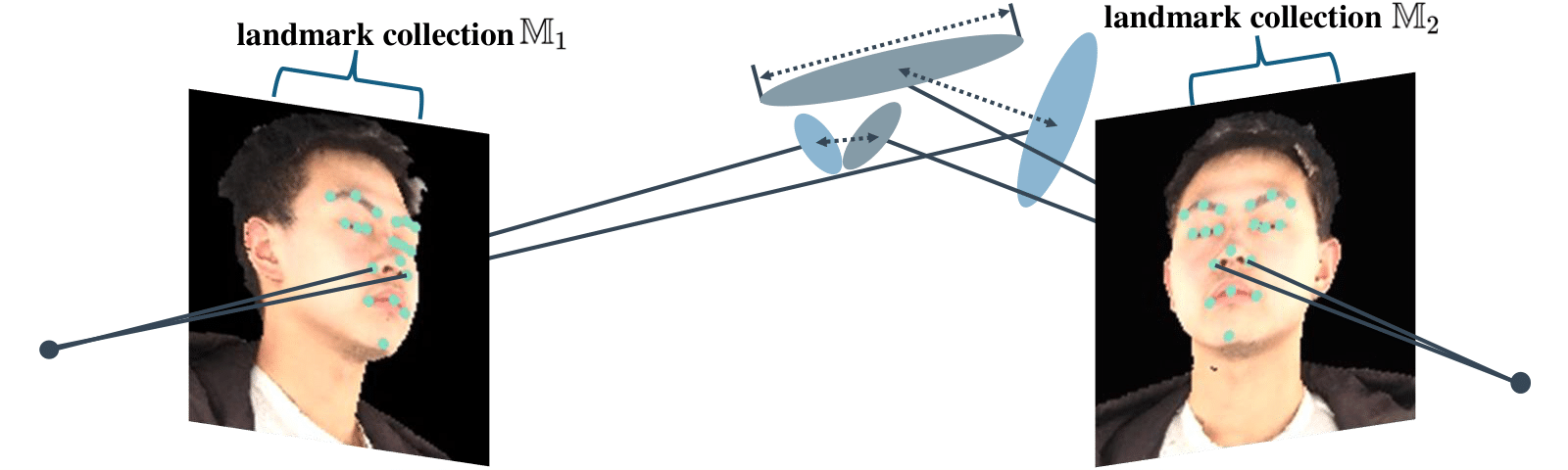
We propose a three-stage pipeline named EVA-Gaussian for 3D human novel view synthesis across diverse camera settings. Specifically, we first introduce an Efficient cross-View Attention (EVA) module to accurately estimate the position of each 3D Gaussian from the source images. Then, we integrate the source images with the estimated Gaussian position map to predict the attributes and feature embeddings of the 3D Gaussians. Finally, we employ a recurrent feature refiner to correct artifacts caused by geometric errors in position estimation and enhance visual fidelity. To further improve synthesis quality, we incorporate a powerful anchor loss function for both 3D Gaussian attributes and human face landmarks. Experimental results on the THuman2.0 and THumansit datasets showcase the superiority of our EVA-Gaussian approach in rendering quality across diverse camera settings.